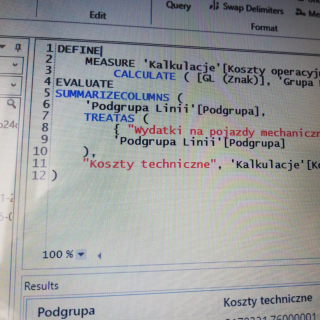
Power BI – import danych z Azure Table Storage
Transkrypt:
W dzisiejszym odcinku zobaczymy, jak odczytywać dane, przechowywane w Azure Storage Table, w Microsoft Power BI. Azure Storage Table to kontenery na dane w Azure Storage (jeden z najprostszych sposobów przechowywania danych w Azure), zachowuje się podobnie jak systemy NoSQL.
W Azure Storage Table zobaczymy tak naprawdę nagłówki rekordów oraz ich zawartości oraz spróbujemy odczytać te informacje. Zacznijmy jednak od eksportu danych z przykładowej bazy AdventureWorksDW, składającej się z kilku tabel wymiarów oraz kilku faktów. Dane przeniosłem do tabel wykorzystując Azure Data Factory. Zobaczymy, jak Power BI dostanie się do nich – jakim sposobem, jak je odczyta i jak potem my zobaczymy te dane już w samym Power BI.
Zobaczmy, jak to wygląda na mojej maszynie. Przechodzę zatem do aplikacji Power BI Desktop, wybieram opcję Get Data. Ta, po rozwinięciu pozwala między innymi na wybranie opcji Azure, która to z kolei posiada podkategorię Azure Storage Table. Wybieramy tę opcję i podłączamy się.
Na początku wpisujemy nazwę mojego konta Azure Storage (tylko pierwszy człon, bo reszta jest identyczna dla wszystkich kont Azure Storage). Podajemy klucz dostępowy, a po jego podaniu powinno pojawić się okno Power Query. Tam wybieramy wszystkie tabele, z których będziemy pobierali dane. Po wybraniu wszystkich widzę trzy kolumny (stałe dla wszystkich tabel) oraz czwartą – taką, która będzie wskazywała zawartość.
Wybrane dane będziemy mogli teraz edytować, wykorzystując Power Query Editor. W aktualnym widoku mamy: klucz partycjonujący, klucz wiersza. Wybrałem unikalne klucze wierszy, ponieważ gdybym w przyszłości chciał zasilać te tabele mogę odnieść się do tych samych wierszy. Table Storage tak naprawdę wystawia unikalną parę – identyfikator wiersza oraz klucz partycjonujący. To na jej podstawie identyfikujemy rekordy. Kolejna kolumna to data aktualizacji rekordu oraz właściwa treść (zawartość) rekordu.
To, co będzie nam potrzebne podczas dalszej analizy to RowKey oraz zawartość wierszy. Zaznaczamy te dwie kolumny oraz wybieramy opcję usunięcia pozostałych. RowKey będzie tak naprawdę SalesQuotaKey, także zmieniam jego nazwę. Aktualnie możemy podejrzeć zawartość rekordów wybierając hiperlink „Record” dostępny w każdym wierszu naszej tabeli (powinniśmy tam zobaczyć kilka pól). Mamy oczywiście możliwość edycji listy kolumn, które znajdują się w każdym z rekordów nagłówkowym. Rozwijamy w tym celu ikonę znajdującą się po prawej stronie w nagłówku kolumny Content. Odznaczając opcję „Use original column name as prefix” i zatwierdzając przyciskiem OK, dodamy kolumny z widoku, przez który przed chwilą przeszliśmy do naszego głównego widoku.
Do dalszej analizy potrzebne będą mi 3 kolumny: DateKey, EmployeeKey, SalesAmountQuota. Nazwa ostatniej kolumny, która była identyczna jak pierwszej, została automatycznie zmieniona podczas eksportu, dlatego też Data Factory wyczyściło nam jej zawartość. Nie będzie nam ona potrzebna do dalszej pracy, toteż usuwamy ją. W przypadku pozostałych należy teraz dopilnować, aby każda z nich zawierała odpowiednie typy danych. Także ostatnia kolumna – SalesAmoutQuota powinna zawierać dane typu liczba zmiennoprzecinkowa. Kolumna EmployeeKey powinna zawierać dane typu liczba całkowita, kolumna DateKey także tego typu. Dla ostatniej kolumny – SalesQuotaKey również wybieramy ten sam typ danych. Teraz tabela, a w zasadzie zapytanie SalesQuota ma wszystkie kolumny, które potrzebujemy.
Na przykładzie tabeli kategorii – dProductCategory postaramy się teraz nieco szybciej przejść przez cały proces. Zaczynamy w ten sam sposób – wybieramy dwie kolumny, które zachowamy. Podobnie, jak w przypadku operacji na poprzedniej tabeli pozostawiamy kolumny RowKey oraz Content, pozostałe dwie usuwamy. Z kolumny Content wyciągamy zawartość, usuwamy ostatnią kolumnę, która zawiera wyłącznie wartości typu null. Zmieniamy nazwę pierwszej kolumny. Skoro tabela nazywa się ProductCategory to podmieniamy jej nazwę na ProductCategoryKey. Zmieniamy także nazwę tabeli z domyślnej na przyjaźniejszą użytkownikowi biznesowemu – Product Category. Następnie podobnie, jak ostatnim razem powinniśmy zmienić typy danych poszczególnych kolumn. Ostatnim razem robiliśmy to „manualnie”, teraz postaramy się zautomatyzować proces. Z górnego menu wybieramy zakładkę Transform. Tam znajdziemy polecenie Detect Data Type i Power BI wykona tę pracę za nas, oczywiście na podstawie pierwszych 1000 rekordów znajdujących się w danej kolumnie w Power Query. Pamiętajmy, że prawidłowe typy danych są niezwykle ważne w modelowaniu. Stąd też potem Power BI wie, jak przechować dane, jak je skompresować, tak aby zajmowały one jak najmniej miejsca. Zawsze sprawdźmy jednak czy Power BI wykrył właściwe typy danych dla każdej z kolumn. Jeśli nie zaznaczmy kolumny do tej operacji to zróbmy to później i ponownie skorzystajmy z polecenia Detect Data Type.
Teraz testowo podobne operacje przeprowadźmy także na tabeli dat. Zmieniamy jej nazwę na Date, pozostawiamy kolumny, które będą nam potrzebne do dalszej pracy. Podobnie, jak ostatnio zmieńmy nazwę pierwszej kolumny. W tym przypadku wybierzmy DateKey. Następnie rozwińmy „tabelę” Content (z jedną mała różnicą – nie zaznaczamy pozycji DateKey, ponieważ znajduje się już ona w naszej wyjściowej tabeli), tak aby jej elementy pojawiły się w naszej bazowej tabeli. Power BI tym razem dość dobrze porozpoznawał typy danych znajdujące się w poszczególnych kolumnach. Możemy to zauważyć przeglądając tabelę wyjściową i ikonki typów danych znajdujące się w polach nazw poszczególnych kolumn. Aby dopilnować poprawności typów danych musimy jedynie zmienić typ danych w FullDateAlternateKey. Potrzebna nam jest tam data, a niepotrzebna godzina.
Następnie podobne czynności wykonajmy dla każdej pozostałej tabeli. W filmie pozwolę sobie przewinąć tę czynność.
Teraz w przypadku tabeli Sales Quota powinienem usunąć kolumnę SalesQuotaKey. Nie będzie ona potrzebna do dalszych analiz, będzie wyłącznie zajmowała cenną przestrzeń. Podobnie, jak widzieliśmy, postępowałem w przypadku tworzenia finalnych tabel faktów. Jak widać było również nie brałem kolumny RowKey do tworzenia tabel końcowych. Powód był identyczny – nie będą one potrzebne do dalszej analizy, a zajmują jedynie cenną przestrzeń.
Po przejściu wszystkich kroków możemy przejść do importu danych. Operacja potrwa chwilę. Kiedy będziemy wiedzieli, że proces powinien niedługo się zakończyć? Każda z tabel faktów (szczególnie Internet Sales oraz Retail Sales) powinna zajmować około 60-70 MB przestrzeni dyskowej. Kiedy będziemy zbliżali się do tej wartości możemy być pewni, że niedługo zakończy się import danych.
Power BI zakończył import danych. Przeanalizował je, to znaczy zweryfikował, które powinny zostać kluczami. Klucze pozwolą nam jednoznacznie identyfikować rekordy, a struktury zostaną takimi lokalnymi gwiazdami.
Sprawdźmy teraz jak Power BI poradził sobie z tym zadaniem. W tym celu, oczywiście w momencie, kiedy nasze dane zostały zaimportowane pomyślnie, wybieramy zakładkę Model, znajdującą się w lewej części ekranu. Naszym oczom ukaże się model naszych danych. Posegregujmy nieco „UML-owy” widok tabel pamiętając, że najważniejsze są z naszej perspektywy: Sales Quota, Reseller Sales oraz Internet Sales. Tabele faktów umieśćmy nieco po środku, inne przemieśćmy tak, aby uzyskać przejrzysty widok modelu danych, wszystkich relacji między tabelami. Sprawdźmy teraz ich poprawność. Power BI generalnie dość dobrze radzi sobie z automatycznym określaniem relacji między poszczególnymi tabelami. Potwierdza to fakt, że w naszym przypadku wyłącznie jedna relacja nie jest poprawna – Power BI połączył automatycznie tabelę Reseller z tabelą Customer. Manualnie usuńmy więc tę połączenie oraz utwórzmy takie pomiędzy Customer a Reseller Sales. Brakuje również kilku relacji, które możemy dodać ręcznie.
Poza widokiem „UML-owym” relacjami możemy także zarządzać wybierając zakładkę Manage Relatioships z górnego menu. Wyświetlamy w ten sposób tabelaryczny widok wszystkich połączeń. Możemy tutaj dodać nową lub usunąć którąś z istntniejących. W naszym przypadku dodamy nową – między tabelą Date oraz Internet Sales. Aby utworzyć relację musimy w każdej z tabel wybrać kolumny, które de facto stanowią relację pomiędzy nimi. W przypadku Date oraz Internet Sales będą to odpowiednio: DateKey oraz OrderDateKey. Wybieramy przycisk OK i tworzymy nową relację. Wychodzimy z widoku tabelarycznego i na naszym schemacie „UML-owym” również powinna się ona pojawić.
Power BI automatycznie nie podłączy nam również tabeli dat z tabelami faktów. Dzieje się tak dlatego, że w przypadku faktów mamy kolumnę o nazwie OrderSalesKey, a w przypadku dat jest to DateKey. Po ręcznym dodaniu relacji otrzymamy w zasadzie gotowy do dalszej (rozszerzenie o miary, wymiary, hierarchie) pracy model danych. Pamiętajmy również zawsze o zmianach nazw tabel, kolumn na przyjazne użytkownikowi biznesowemu. Power BI zwykle je pobiera z danych źródłowych.
Dziękuję za uwagę i zapraszam na kolejny odcinek.